키워드
소켓, 바이트 스트림, 데이터 송수신, HTTP, 클라이언트, 서버, accept ,write, read, close
Socket 이란
Socket은 양 끝단에서 바이트 스트림을 통해 데이터를 주고 받는 도구로 인터페이스 역할을 한다.
소켓은 연결을 맺기 위한 IP와 Port 그리고 어떻게 데이터를 주고 받을지를 약속한 프로토콜로 정의되고, 역할에 따라 Server Socket과 Client Socket으로 구분된다.
HTTP 통신과 Socket 통신의 차이점
데이터를 주고 받으려면 HTTP를 이용한 통신도 있지않은가? 왜 socket 통신이 필요한가?
- HTTP 통신은 단방향 통신이다.
Client의 요청이 있을 때에만, Server가 응답하여 데이터를 전송하고 곧바로 연결을 종료한다.
서버의 응답에는 응답 코드가 같이 전송되며, 응답 코드와 메시지 바디를 통해 요청한 값을 전달받는다.
( + HTTP 통신은 매번 요청과 응답 사이에 커넥션은 맺고 끊어야하는데, 그 비용이 비싸서 최근에는 Keep Alive 옵션을 통해 일정 기간 동안 Client와 Server의 커넥션을 유지하는 방식의 통신을 한다.)
- Socket 통신은 양방향 통신이다.
Client와 Server가 특정 포트를 통해서 이어져 있기 때문에 양방향 통신이 가능하다. Client의 요청에 따른 응답만을 데이터로 주는 것이 아니라, Client와 Server는 실시간으로 데이터를 주고 받을 수 있다.
실시간 동영상 스트리밍이나 온라인 게임과 같은 경우에 사용한다.
여기까지가 둘의 차이점이고 더 깊게 들어가면 이렇다.
HTTP도 결국 소켓 통신이다. 소켓은 IP와 Port 를 사용해 만든 통신의 양 끝단인데, TCP 레이어 위에 올라간 HTTP 또한 같은 방식으로 통신한다. HTTP 통신의 내부 구현에서는 소켓을 사용한다.
하지만, 둘을 구분하는 이유는 한 쪽(Client)에서만 요청을 하고 응답을 하는 웹 통신의 특성상 HTTP가 하나의 중요한 프로토콜로 구분이 되었기 때문이다.
즉, HTTP 통신은 소켓 통신의 일종이지만, 소켓 통신이 HTTP 통신인 것은 아니다.
소켓 통신의 흐름

Server (서버)
1. Socket() - 소켓을 생성
2. bind() - 소켓 주소 할당
3. listen() - 클라이언트 접근 요청에 수신 대기열 생성
4. accpet() - 클라이언트와의 연결 대기
5. 데이터 송수신 후, close()로 소켓 종료
Client (클라이언트)
1. Socket() - 소켓을 생성. 이 때, 통신을 맺을 호스트(서버)의 IP와 Port 할당
2. connet() - 소켓 연결 요청
3. 데이터 송수신 후, close()로 소켓 종료
기본적인 소켓 통신 코드
소켓이 뭔지 알았으니 기본적인 소켓 통신 코드를 보자.
- Server
public class SocketServer {
private int port = 4545;
public void server(){
try {
// 서버 소켓 생성 Port 할당
ServerSocket serverSocket = new ServerSocket(port);
// 클라이언트 연결 대기.
Socket socket = serverSocket.accept();
// 데이터 송수신 스트림 생성
InputStream is = socket.getInputStream();
OutputStream os = socket.getOutputStream();
// 바이트 배열 생성 후 바이트 배열만큼 read
byte[] buffer = new byte[1024];
int bytesRead = is.read(buffer);
// 만약 InputStream 에서 읽을 값이 없으면 -1 을 반환한다.
if (bytesRead != -1) {
// 버퍼 배열 처음부터 받은 데이터 까지로 문자열 생성
String message = new String(buffer, 0, bytesRead);
System.out.println("recieved Message from client socket: " + message);
String responseMessage = "Success.";
os.write(responseMessage.getBytes());
}
//소켓 종료
socket.close();
} catch (IOException e) {
throw new RuntimeException(e);
}
}
- Client
public class SocketClient {
public void client() {
try {
// host IP와 Port 할당
Socket socket = new Socket("127.0.0.1", 4545);
// 데이터 송수신을 위한 스트림 생성
InputStream is = socket.getInputStream();
OutputStream os = socket.getOutputStream();
String message = "send message ... from client socket";
// 데이터 송신
os.write(message.getBytes());
// 서버로부터의 응답 수신
byte[] buffer = new byte[1024];
int bytesRead = is.read(buffer);
if (bytesRead != -1) {
String responseMessage = new String(buffer, 0, bytesRead);
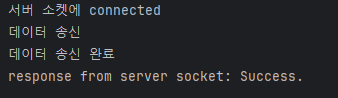
System.out.println("response from server socket: " + responseMessage);
}
// 소켓 종료
socket.close();
} catch (IOException e) {
throw new RuntimeException(e);
}
}
}
결과
- Server

- Client
정리
가장 앞서 작성했던 키워드 기반으로 정리해보자.
소켓은 양 끝단에서 바이트 스트림을 기반으로 데이터를 송수신 할 수 있도록 하는 도구이다. 데이터를 송수신할 수 있는 방법으로 HTTP통신도 있지만, HTTP는 클라이언트에서 서버로 요청할 때, 요청한 부분에 대한 값을 응답하는 구조로 이루어졌다. 즉, 단방향 통신이다. 소켓 통신은 아이피,포트,프로토콜로 정의되며 연결되어 있으면 양방향으로 데이터 송수신이 가능하다. 소켓은 역할에 따라 클라이언트 소켓, 서버 소켓으로 구분된다.
클라이언트 소켓은 소켓을 생성한 뒤, 서버 소켓으로 연결하여 데이터를 송수신한다.
서버 소켓은 소켓을 생성하고, 클라이언트 측의 연결을 대기하고 연결되면 데이터를 송수신한다.
바이트 스트림을 기반으로 데이터를 송수신한다.
InputStream 은 바이트의 입력을 처리한다. 보내고자 하는 데이터를 바이트 배열을 이용해서 저장하고 전송하게 되는데..
얼만큼의 데이터를 다뤄야할지 모르는 상태라면, 넉넉하게 배열을 선언하면 다인가? 1000으로 선언한 바이트 배열중에 20만 사용되면 980은 낭비되는 데이터 아닌가? 얼만큼의 데이터가 전송될지 모르는 가변적인 데이터를 보내야할 때는?
바이트 스트림과 보조 스트림 , 문자 기반 스트림을 활용하여 문제를 해결해야한다.
2024.02.29 - [JAVA] - [Java] 입출력 스트림(I/O Stream) 쉽게 정리
[Java] 입출력 스트림(I/O Stream) 쉽게 정리
키워드 개울, 고속도로, 흐른다, 단방향, 선입선출, 연결, 통신, 바이트 스트림, 보조 스트림 , 스트링 스트림 입출력? 컴퓨터 내부 또는 외부의 장치와 프로그램 간에 데이터를 주고 받는 것. Input
burning-man.tistory.com
'JAVA' 카테고리의 다른 글
| [Java] 입출력 스트림(I/O Stream) 쉽게 정리 (0) | 2024.02.29 |
|---|